

Voice at the wheel: Study introduces an encoder-decoder framework for AI systems
phys.org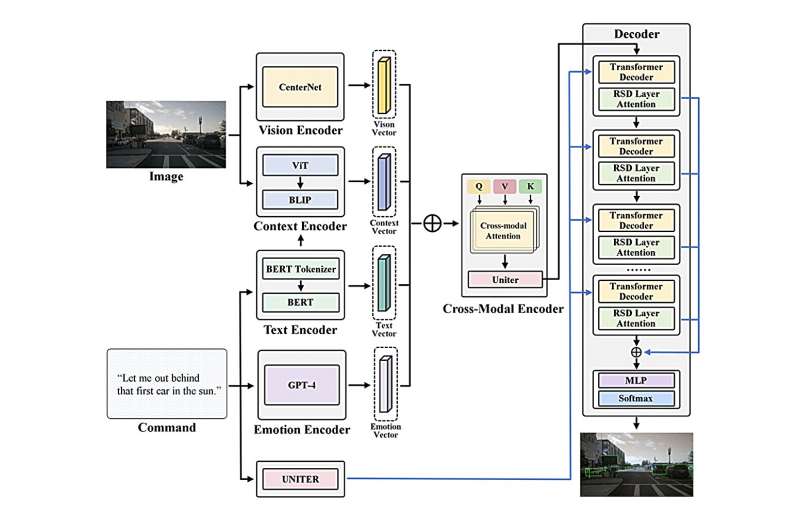
Recently, the team led by Professor Xu Chengzhong and Assistant Professor Li Zhenning from the University of Macau's State Key Laboratory of Internet of Things for Smart City unveiled the Context-Aware Visual Grounding Model (CAVG).
This model stands as the first Visual Grounding autonomous driving model to integrate natural language processing with large language models. They published their study in Communications in Transportation Research.
Amidst the burgeoning interest in autonomous driving technology, industry leaders in both the automotive and tech sectors have demonstrated to the public the capabilities of driverless vehicles that can navigate safely around obstacles and handle emergent situations.
Yet, there is a cautious attitude among the public towards entrusting full control to AI systems. This ...
Copyright of this story solely belongs to phys.org . To see the full text click HERE