

Master Generative AI Evaluation: From Single Prompts to Complex Agents
google cloudblog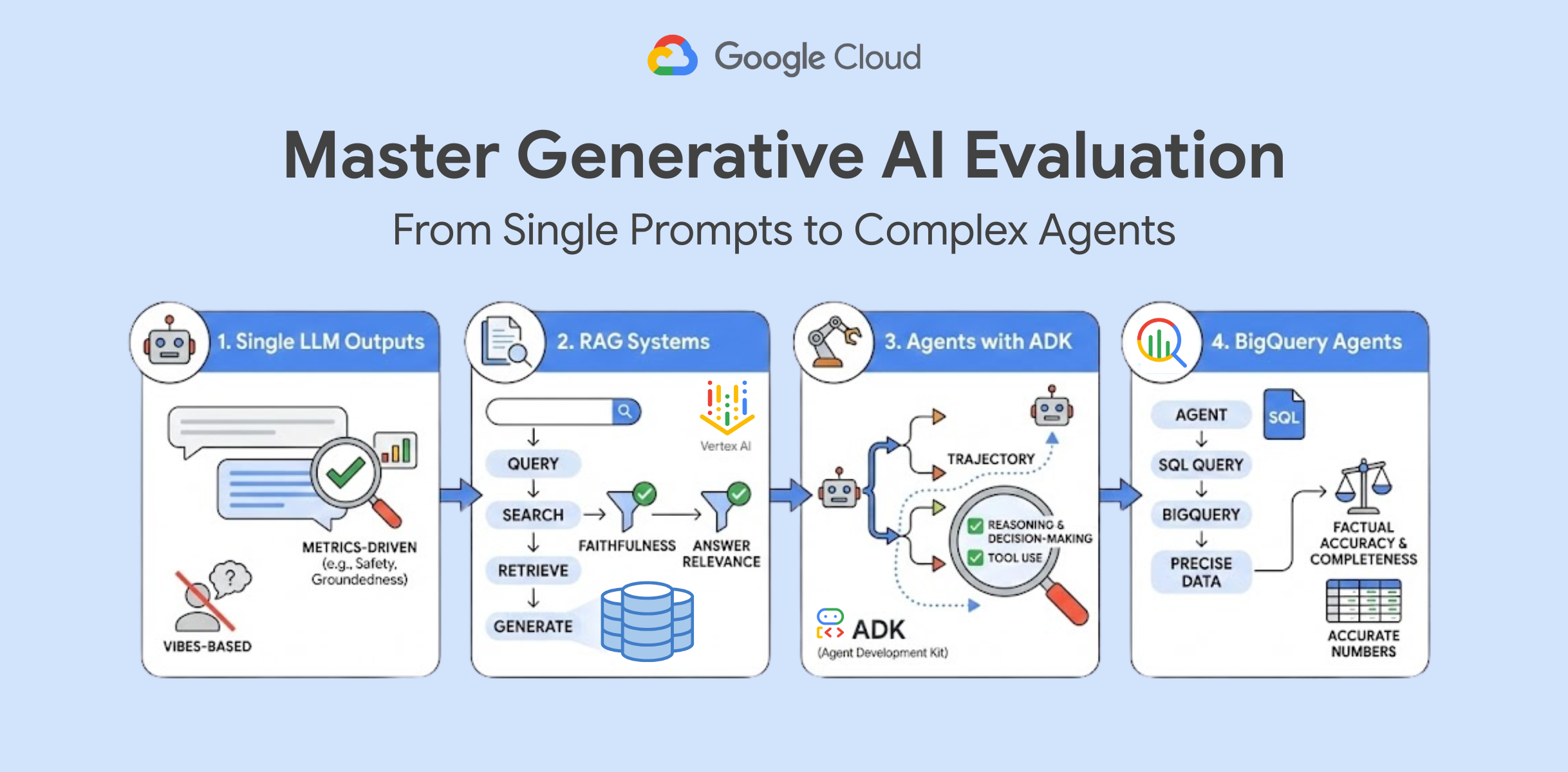
Building Generative AI applications has become accessible to everyone, but moving those applications from a prototype to a production-ready system requires one critical step: Evaluation.
How do you know if your LLM is safe? How do you ensure your RAG system isn't hallucinating? How do you test an agent that generates SQL queries on the fly?
At its core, GenAI Evaluation is about using data and metrics to measure the quality, safety, and helpfulness of your system's responses. It moves you away from "vibes-based" testing (just looking at the output) to a rigorous, metrics-driven approach using tools like Vertex AI Evaluation and the Agent Development Kit (ADK).
To guide you through this journey, we have released four hands-on labs that take you from the basics of prompt testing to complex, data-driven agent assessment.
Evaluating Single LLM Outputs
Before you build complex systems, you must understand how to evaluate ...
Copyright of this story solely belongs to google cloudblog . To see the full text click HERE