

How Context Changes the Way We Rate AI Responses
hackernoon.comThis study investigates how varying the amount and type of dialogue context affects the consistency and quality of crowdsourced relevance and usefulness judgments in AI evaluation.
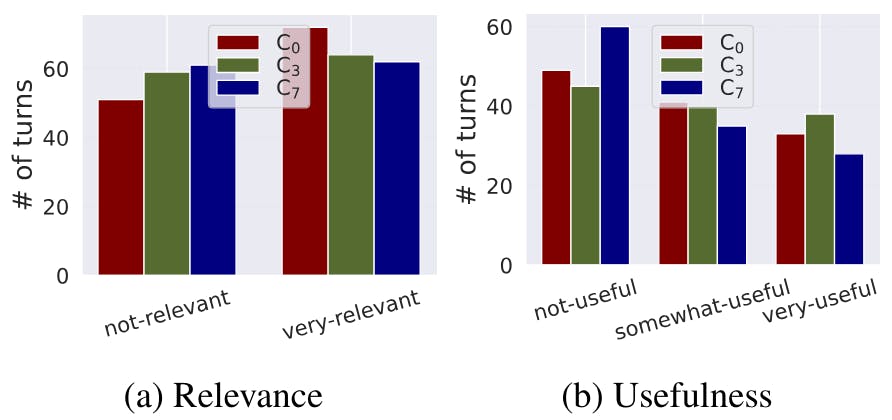
Table of Links
2 Methodology and 2.1 Experimental data and tasks
2.2 Automatic generation of diverse dialogue contexts
3 Results and Analysis and 3.1 Data statistics
3.2 RQ1: Effect of varying amount of dialogue context
3.3 RQ2: Effect of automatically generated dialogue context
6 Conclusion, Limitations, and Ethical Considerations
7 Acknowledgements and References
2.3 Crowdsource experiments
Following (Kazai, 2011; Kazai et al., 2013; Roitero et al., 2020), we design human intelligence task (HIT) templates to collect relevance and usefulness labels. We deploy the HITs in variable conditions to ...
Copyright of this story solely belongs to hackernoon.com . To see the full text click HERE