How we cut Vertex AI latency by 35% with GKE Inference Gateway
As generative AI moves from experimentation to production, platform engineers face a universal challenge for ...


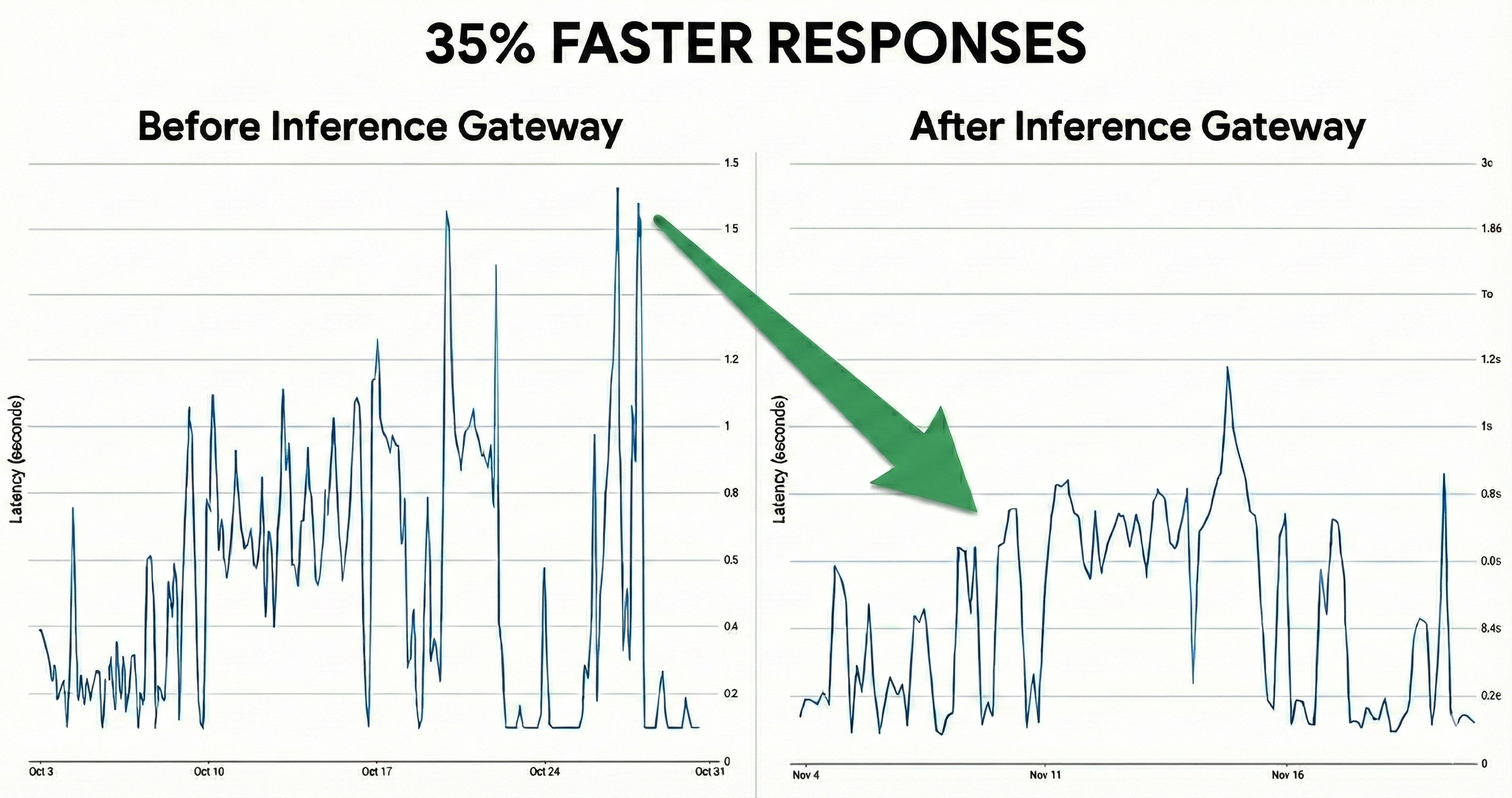
As generative AI moves from experimentation to production, platform engineers face a universal challenge for ...